GSoC实录:为openSUSE打造本地离线智能助手
项目起源:一个简单却关键的问题
今年 Google Summer of Code 项目中,我们从一个朴素的疑问出发:一位刚接触 openSUSE 的用户,能否在不将问题或机器信息发送到云端的前提下,获得针对自身系统的实用帮助?
核心思路是将运行在用户本地的小型语言模型(SLM)与官方 openSUSE 文档的检索相结合。助手不能只给出泛泛的 Linux 建议,它应该清楚当前机器运行的是 Leap 版本、是否使用了 Btrfs 和 Snapper、安装了什么 GPU、哪些服务启动失败。然后,它能依据适用于该系统的文档,解释诸如 zypper、YaST、Snapper 和 firewalld 等工具的具体用法。
在中期检查阶段,这个核心流程已在 openSUSE Leap 16.0 虚拟机上正常运转。助手完全在本地执行,通过本地 LanceDB 索引检索 openSUSE 文档,读取选定的主机上下文信息,并且同时提供了命令行界面和 Web 用户界面。更关键的是,它现在运行在基于 openSUSE BCI 的容器中(由 Open Build Service 构建),即使虚拟机没有任何出站互联网访问也能正常工作。
从小型概念验证到真实的 Leap 部署
在 GSoC 开始前,项目使用 TinyLlama、ChromaDB 和一小部分文档验证了基本架构的可行性。这足以做一次演示,但远不能回答分发特性所关心的实际问题:哪个模型在纯 CPU 硬件上表现良好?助手如何安装?目标机器无法下载模型时该怎么办?容器能否在未授予多余权限的情况下检查宿主机?
导师提供的测试虚拟机让这些问题变得具体。该虚拟机运行 Leap 16.0,配备 4 个 vCPU 和 15 GB 内存,没有 GPU,也无法访问互联网。这是一个理想的测试目标,因为它能避免我们意外依赖云端 API 或开发者本地的缓存数据。
当前请求处理路径如下:
- 用户在 CLI 或 Gradio Web 界面输入问题。
- 助手从宿主机读取相关的非敏感系统信息。
- MiniLM 嵌入模型从本地 LanceDB 索引中检索匹配的文档块。
- 系统提示将用户问题、宿主机上下文和检索到的来源合并。
- 本地 GGUF 模型通过
llama.cpp生成回答。 - 回答中附带了所用文档的引用来源。
目前索引包含 1982 个文档块,来自 Leap 入门指南、参考手册、Leap 16.0 发布说明以及选定的 openSUSE 维基 SDB 页面。SDB 集合覆盖了常见领域,如软件仓库、升级、音频、NVIDIA 驱动程序以及 SUSE Prime 故障排除。
模型选择:靠测量而非猜测
首要任务之一是替换 TinyLlama,寻找能在普通硬件上给出可靠管理指导的模型。我们设计了模型分级,并在 Leap 虚拟机上通过完整的 RAG 和系统上下文流水线对 6 个 GGUF 模型进行了基准测试。
每个模型回答了 8 个相同的 openSUSE 入门问题。生成过程在虚拟机内离线运行,而评判过程则独立进行:使用 Gemini 2.5 Flash-Lite 对保存的回答进行评分,结合参考答案和预期事实清单。将这两个步骤分离意味着,如果评分方法发生变化,无需重新执行缓慢的 CPU 生成过程。
基准测试的环境与公开部署一致:4 个 vCPU、15 GB 内存、无 GPU,生成期间无网络访问。下表中的“延迟”是指每个完整回答(包括检索和基于检索文档与宿主机上下文构建提示)的平均时间。
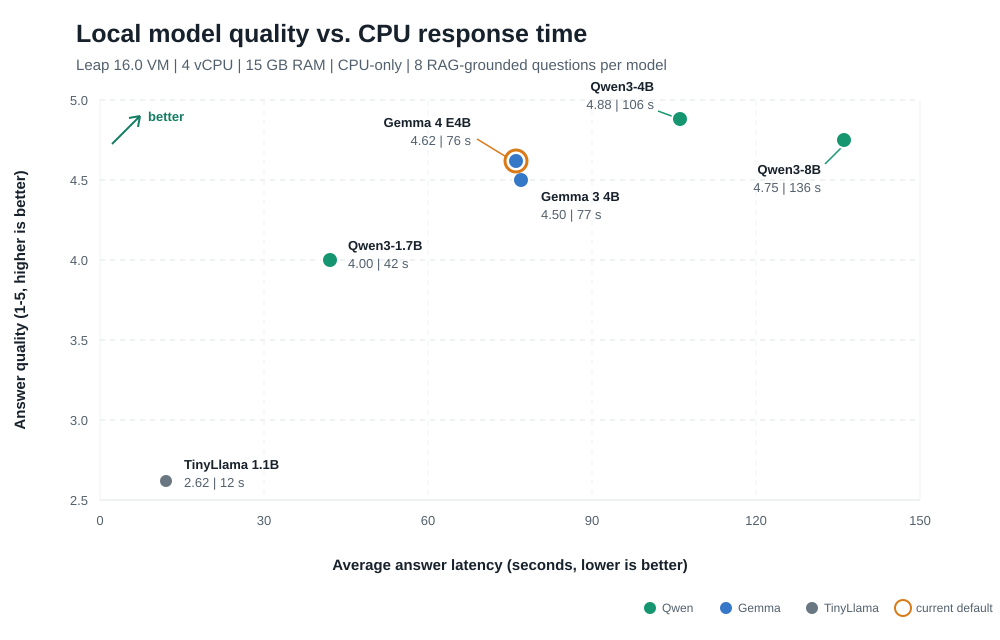
图中位置越高、越靠左表示效果越好。Qwen3-4B 的评判质量最高;Gemma 4 E4B 是当前默认模型,回答速度快约 30 秒。橙色圆圈标记了当前默认模型。
各模型性能概览
- Qwen3-4B-Instruct:质量评分 4.88,平均延迟 106 秒
- Qwen3-8B:质量评分 4.75,平均延迟 136 秒
- Gemma 4 E4B:质量评分 4.62,平均延迟 76 秒(当前默认)
- Gemma 3 4B:质量评分 4.50,平均延迟 77 秒
- Qwen3-1.7B:质量评分 4.00,平均延迟 42 秒(适合低资源机器)
- TinyLlama 1.1B:质量评分 2.62,平均延迟 12 秒(仅用于冒烟测试)
结果表明,更大的模型并不自动成为更好的默认选择。Qwen3-4B 比 Qwen3-8B 评分稍高且快约 30 秒。Gemma 4 E4B 提供了不错的延迟/质量折中,经导师讨论后成为当前标准模型的默认选项。Qwen3-1.7B 仍适合低配机器,而 TinyLlama 仅用于基本功能验证。
完整的评测方法和每个模型的详细分析见评测报告。
这些时间数据也促使我们改进了 Web 界面。70~120 秒的回答生成时间,如果界面没有任何反馈,用户很容易认为程序已卡死。现在界面会显示当前选中的模型级别、说明首次提问时模型正在加载、展示已经过的生成时间,并且更清晰地提示模型或索引数据缺失的情况。
“离线”不只是在本地运行模型
到目前为止学到的最重要的一课是:本地推理和离线安装是两码事。
GGUF 模型一旦下载完毕,确实可以脱离网络运行。但要打造一个可用的助手,还需要嵌入模型、Python 和原生库、文档索引、配置文件以及兼容的文件权限。虚拟机没有互联网接入,迅速暴露了所有隐藏的下载依赖。
为了让运行状态一目了然,我们添加了 suse-assist doctor 命令。它可以检查模型文件、向量存储、嵌入缓存、内存和磁盘空间、宿主机挂载、离线环境设置、Web 端口以及容器运行时。我们还增加了 suse-assist setup 命令,用于选择模型级别、准备模型和索引、可选地导入离线数据,并执行最终检查。
对于那些在安装过程中无法下载资源的机器,项目现在提供了离线捆绑包格式:
(以下内容涉及更具体的离线部署细节,因原文截取未完整呈现,但核心思路已在上述段落中体现。)
关注微信号:智享开源 ,及时了解更新信息。
原文链接:https://news.opensuse.org/2026/06/29/building-local-offline-opensuse-assistant/
评论列表
为您推荐





请支持IMCN发展!
| 微信捐赠 | 支付宝捐赠 |
|---|---|
 |
 |
 扫码关注公众号:智享开源
扫码关注公众号:智享开源最新科技信息


归档
近期评论
- · 热烈祝贺04-16
- · imcn成功拥抱人工...04-16
- · Zorin OS 很...04-16
- · elementary...12-09
- · 写个桌面启动器创建工...11-30
评论功能已经关闭!